- Posted
- Categories
-
- OpenPrescribing Hospitals
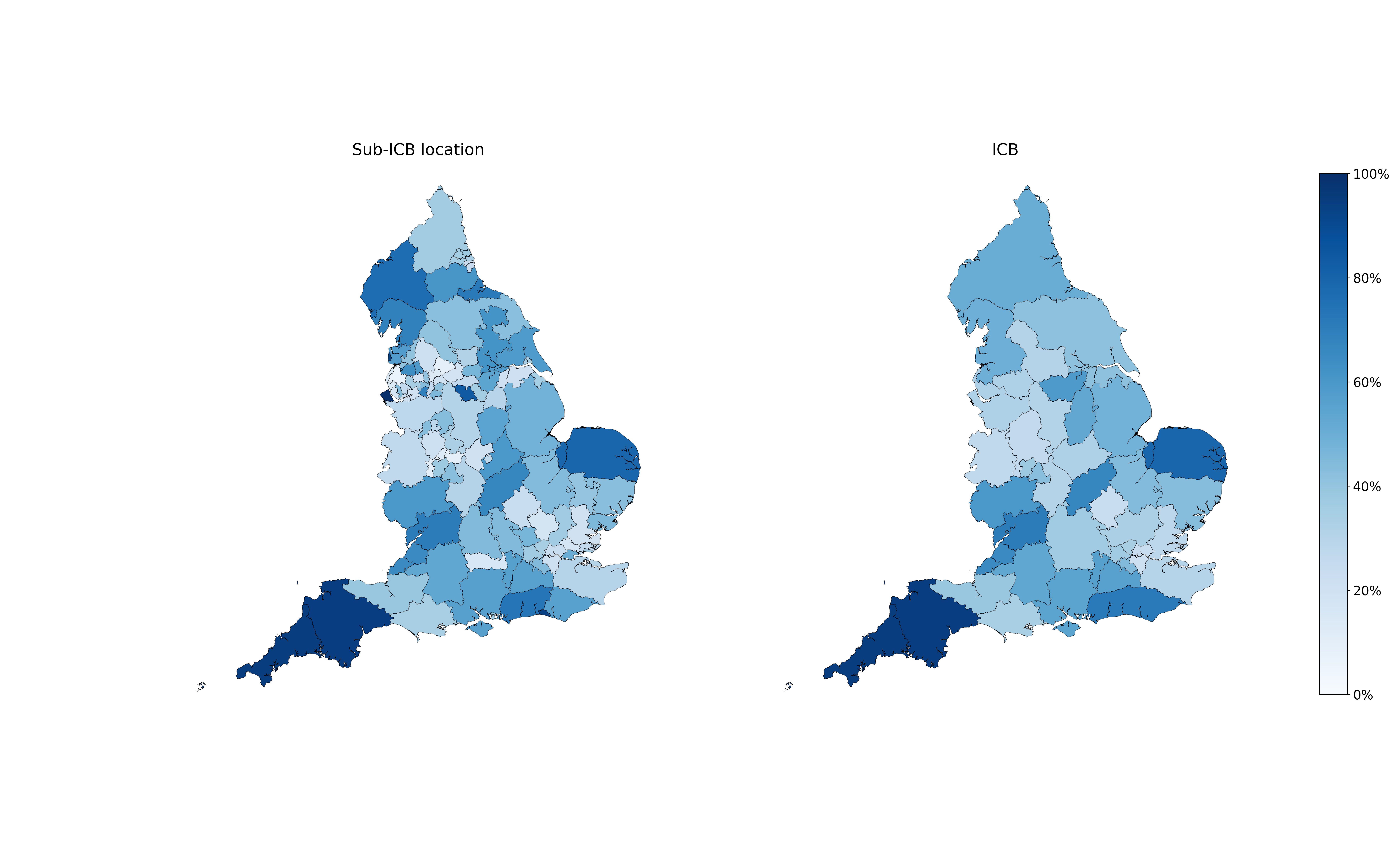
We're going to build OpenPrescribing for hospitals: here's why
We’re going to build OpenPrescribing for hospitals using openly available secondary care medicines data. Here we explain why and what you can expect.